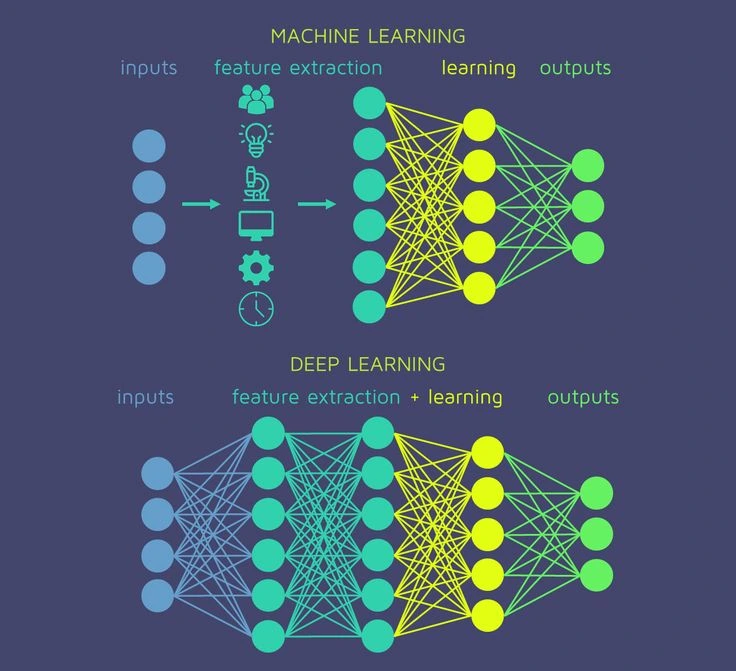
A Beginner’s Guide to Neural Networks
Neural networks are at the heart of many recent advancements in artificial intelligence (AI), powering technologies from voice recognition to self-driving cars. But what exactly are neural networks, and how do they work? If you're new to this fascinating area, this guide will provide you with a solid foundation in the basics of neural networks, their structure, and how they’re trained to solve complex problems.
What is a Neural Network?
A neural network is a computational model inspired by the structure and function of the human brain. It consists of layers of interconnected nodes, called neurons, which work together to process data, recognize patterns, and make decisions. Neural networks are a subset of machine learning and are particularly good at tasks that involve image recognition, natural language processing, and other areas where traditional algorithms struggle.
The Building Blocks of a Neural Network
- Input Layer: The input layer is where the data enters the network. Each neuron in this layer represents a feature or variable from the dataset. For example, if you are training a network to recognize handwritten digits, the input layer would consist of pixels from the images.
- Hidden Layers: Hidden layers sit between the input and output layers. Each neuron in a hidden layer receives input from the previous layer, processes it, and passes the result to the next layer. The hidden layers perform mathematical computations that allow the network to learn and recognize patterns. A neural network can have one or multiple hidden layers, depending on the complexity of the problem.
- Output Layer: The output layer provides the final prediction or classification. For example, in a network trained to classify images of animals, the output layer might have neurons representing different animal classes, such as “cat,” “dog,” or “bird.” The neuron with the highest output value determines the network's prediction.
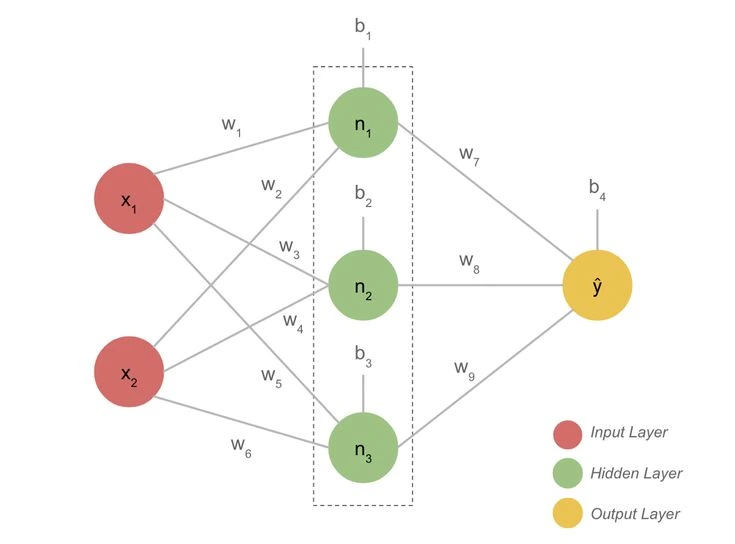
Each neuron in a layer is connected to neurons in the adjacent layers. These connections have associated weights, which determine the strength and importance of the connections.
How Do Neural Networks Learn?
Neural networks learn by adjusting the weights of the connections between neurons. This process is called training and involves the following steps:
- Forward Propagation: In forward propagation, data flows from the input layer through the hidden layers to the output layer. Each neuron receives inputs, multiplies them by their weights, and applies an activation function to produce an output. This output is passed to the next layer until the data reaches the output layer.
-
Activation Functions: Activation functions introduce non-linearity into the
network, allowing it to learn more complex patterns. Common activation functions include:
- Sigmoid: Outputs values between 0 and 1, useful for binary classification tasks.
- ReLU (Rectified Linear Unit): Outputs the input if it’s positive, otherwise returns 0. ReLU is popular because it helps mitigate the vanishing gradient problem.
- Softmax: Used in the output layer for multi-class classification, it converts raw scores into probabilities.
- Calculating the Loss: The network compares its predictions with the actual labels to calculate the loss (error). The loss function measures how far off the predictions are from the expected values. Common loss functions include Mean Squared Error for regression tasks and Cross-Entropy for classification tasks.
- Backpropagation: Backpropagation is the process of adjusting the weights to minimize the loss. It works by calculating the gradient of the loss function with respect to each weight, using a method called gradient descent. The network then updates the weights in the opposite direction of the gradient, gradually reducing the error.
- Gradient Descent: Gradient descent is an optimization algorithm that helps the network find the best set of weights by taking small steps toward minimizing the loss function. Variants of gradient descent, like Stochastic Gradient Descent (SGD) and Adam, are used to speed up convergence and improve accuracy.
Types of Neural Networks
There are various types of neural networks, each suited for different tasks:
- Feedforward Neural Networks: The simplest type of neural network, where data flows in one direction from input to output. They are commonly used for tasks like image classification and regression.
- Convolutional Neural Networks (CNNs): CNNs are specialized for processing grid-like data, such as images. They use convolutional layers to detect features like edges, shapes, and textures. CNNs are widely used in image recognition, object detection, and video analysis.
- Recurrent Neural Networks (RNNs): RNNs are designed for sequential data, where the order of inputs matters, such as in time series or natural language. They have connections that loop back, allowing them to retain information from previous steps. RNNs are commonly used for tasks like language translation, speech recognition, and stock price prediction.
- Generative Adversarial Networks (GANs): GANs consist of two networks, a generator and a discriminator, that work together to generate realistic data, such as images or audio. GANs are widely used in creative applications, such as generating artwork or deepfake videos.
- Transformers: Transformers are a recent innovation that has revolutionized natural language processing. They use attention mechanisms to weigh the importance of different parts of the input data. Transformers are used in language models like GPT-3 and BERT, enabling tasks like text generation, summarization, and translation.
Training and Evaluating a Neural Network
- Data Preparation: Neural networks require large datasets to learn effectively. The data is typically split into training, validation, and test sets. The training set is used to adjust the weights, the validation set helps fine-tune hyperparameters, and the test set evaluates the model’s performance.
- Training the Model: Training involves feeding the training data into the network, calculating the loss, and updating the weights using backpropagation. This process is repeated over multiple epochs until the network achieves satisfactory performance.
- Evaluating the Model: After training, the network is evaluated on the test set to measure its accuracy, precision, recall, or other relevant metrics. If the model performs well on the test data, it is likely to generalize well to new, unseen data.
- Fine-Tuning and Regularization: Fine-tuning involves adjusting hyperparameters, such as learning rate or batch size, to improve performance. Regularization techniques, such as dropout or L2 regularization, help prevent overfitting, ensuring that the model performs well on both training and test data.
Applications of Neural Networks
Neural networks have a wide range of applications across various industries:
- Healthcare: Neural networks are used in medical image analysis, drug discovery, and predicting patient outcomes.
- Finance: They assist in fraud detection, algorithmic trading, and credit scoring.
- Autonomous Vehicles: Neural networks power self-driving cars, enabling them to perceive their surroundings and make driving decisions.
- Natural Language Processing: They are employed in chatbots, sentiment analysis, and machine translation.
- Gaming: Neural networks enhance game AI, making non-player characters (NPCs) behave more intelligently.
Conclusion
Neural networks have transformed the field of artificial intelligence and are continuously evolving. As technology advances and datasets grow larger, neural networks will play an increasingly vital role in solving complex problems and driving innovation across various sectors. Whether you’re a beginner or an experienced practitioner, understanding the basics of neural networks is essential for navigating the future of AI.