Top Machine Learning Algorithms Explained
Machine learning has become an essential tool for businesses and researchers alike, providing methods to automatically analyze data and make predictions. Whether you're new to machine learning or looking to deepen your understanding, it’s valuable to know about some of the most commonly used algorithms. This guide will walk you through the top machine learning algorithms, grouped into categories, to help you understand how they work and where they're applied.
1. Linear Regression
Type: Supervised Learning
Description: Linear regression is one of the simplest and most interpretable
algorithms. It attempts to model the relationship between a dependent variable and one or more
independent variables by fitting a linear equation to observed data.
Applications: Forecasting, risk analysis, and trend analysis.
2. Logistic Regression
Type: Supervised Learning
Description: Despite its name, logistic regression is used for classification
tasks. It models the probability that a given input belongs to a particular category by applying
a logistic function.
Applications: Binary classification tasks such as spam detection, fraud
detection, and disease prediction.
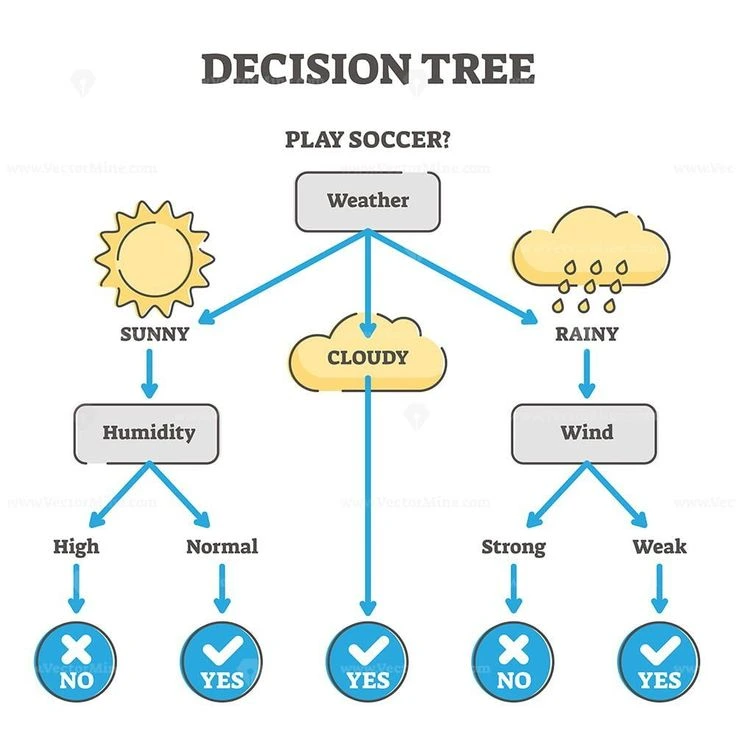
3. Decision Trees
Type: Supervised Learning
Description: Decision trees create a model that predicts the value of a target
variable by learning simple decision rules derived from data features. They’re easy to interpret
and can handle both categorical and continuous data.
Applications: Customer churn prediction, medical diagnosis, and credit risk
analysis.
4. Random Forest
Type: Supervised Learning (Ensemble Method)
Description: A random forest is a collection of decision trees that work together
to improve accuracy and reduce overfitting. It builds multiple trees and merges their results to
produce a more accurate and stable prediction.
Applications: Image classification, stock market predictions, and customer
segmentation.
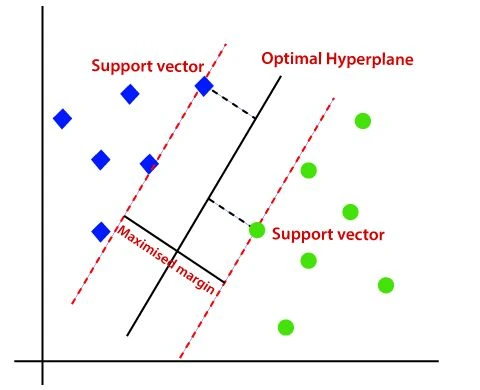
5. Support Vector Machines (SVM)
Type: Supervised Learning
Description: SVMs are powerful classification algorithms that find the hyperplane
that best separates classes in the feature space. They work well in high-dimensional spaces and
are effective when there’s a clear margin of separation between classes.
Applications: Face detection, text categorization, and bioinformatics.
6. K-Nearest Neighbors (KNN)
Type: Supervised Learning
Description: KNN is a simple yet powerful algorithm that classifies new data
points based on the majority class of their nearest neighbors. It’s highly interpretable but can
be computationally expensive with large datasets.
Applications: Recommender systems, image recognition, and customer behavior
analysis.
7. K-Means Clustering
Type: Unsupervised Learning
Description: K-Means is a clustering algorithm that partitions data into K
clusters based on feature similarity. It assigns data points to clusters by minimizing the sum of
squared distances between data points and their cluster centroid.
Applications: Market segmentation, document clustering, and image compression.
8. Principal Component Analysis (PCA)
Type: Unsupervised Learning (Dimensionality Reduction)
Description: PCA reduces the dimensionality of large datasets by transforming
data into a set of orthogonal components that capture the maximum variance. It helps to simplify
datasets, making them easier to visualize and analyze.
Applications: Data visualization, noise reduction, and feature extraction.
9. Naïve Bayes
Type: Supervised Learning
Description: Naïve Bayes is a probabilistic classifier based on Bayes' theorem.
It assumes independence between features, making it fast and efficient for large datasets.
Applications: Sentiment analysis, document classification, and email filtering.
10. Reinforcement Learning (Q-Learning)
Type: Reinforcement Learning
Description: In reinforcement learning, agents learn by interacting with an
environment and receiving feedback in the form of rewards or penalties. Q-Learning is a popular
algorithm where agents learn to take optimal actions by maximizing cumulative rewards.
Applications: Game AI, robotics, and autonomous driving.
Diagram Description
The diagram for these algorithms can be structured as follows:
- Title: Types of Machine Learning Algorithms
- Sections: Three main sections: Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
- Each section contains specific algorithms discussed above. You can use flow lines or arrows from each algorithm to showcase connections or similarities.
Conclusion
Understanding these algorithms provides a solid foundation for exploring machine learning applications. Each algorithm has its strengths and weaknesses, and the choice of algorithm often depends on the specific problem and the nature of the data.